Poker
Command Line Texas Hold ‘em [Under Development]
Game Play (Quick Hold ‘em Overview)
User will play up to 3 bots at a time. Each player begins with the same 5000 chips. After every player chooses to buy in (and eventually if I get to it, have big/small blinds) a round of betting, checking or folding occurs.
Three cards, called the flop, are dealt to the table. These cards are common to all players. After an additional round of player actions, a fourth card is dealt to the table. Again, each player at the table is given the choice of checking, betting or folding. Finally, a fifth card called the River is dealt to the table. After the final round of bets the players show their cards and the winner takes all.
In the case of a tie the pot (sum of all bets made during round) is split between players.
AI Development Strategy
There are a finite number of cards, and a finite possible combination of cards that make up all the valid states of every poker hand. This is great because it means that the end goal of finding the best possible hand from a Bot’s two pocket cards, and the 5 table cards can be modeled as a series of Markov state transitions [initial hands, the flop, turn and river].
Creating Training Data
Using the AI class I generate large samples of training data, containing 4 states. The first being the two cards dealt to a player, the second is the flop, the third the turn and the fourth the river and the whole table. The values are comma separated, and saved into the training.txt file.
Pre-Processing the Data
First the training data is labeled with a classification class written in Java called Neuron. This classifier is unsupervised, and will likely become relevant again downstream. For now it simply labels the training data.
After passing through Neuron, the training data has been properly labeled and is therefore ready a more complicated Neural Network structure that will be written in Python.
Learning From Training Data
The goal is that by providing a network with a very large set of 4 consecutive sequences of Cards, with a final logical outcome label, the intent is to create an ability to use Decision Trees and AutoEncoding to select favorable actions at any given state (based on the learned knowledge of which decisions are best).
To do this, the program will first start generating lots of random hands, and figure out the distribution of Poker hands that emerge from the sequence of cards dealt during the round. As a more precise distribution of hands grows as the number of total sample hands grows, the decision making process for potential options at each given state (Pre-Flop, Flop, etc.) depending on the hand dealt.
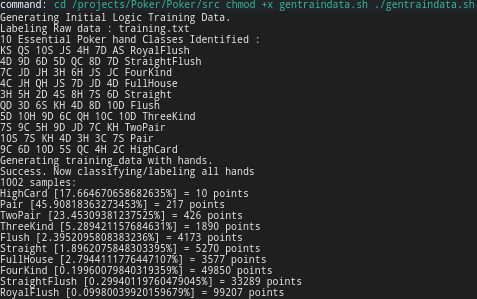
At about 1000 Hands we find that NO Royal Flushes were dealt. On the other end, about 20% of the time no hands were hit (only high card). The bulk of the distribution is at a Pair ~43% of the time, Two Pair ~25% of the time, 3 of a Kind at ~5%, Flush was dealt ~2% of the time, Full House ~3% of the time, and a Four of a Kind and Straight Flush were dealt less than 1% of the time. Upon initial inspection this distribution seems fairly realistic for what a play could expect to be dealt after 1000 hands.
Using these odds we assign initial weights to each hand as shown below.
AI Development: Computers Counting Cards
At this point, the program is capable of generating lots of training data, labeling and classifying this data, and making some initial observations about the output. The next step will be to start looking at each STATE with respect to the final outcome, and start using knowledge of outcomes to start creating weights based on the expectations the program has about what could happen based on what already has happened.
Training data is created and labeled with the gentraindata.sh script.